Python操作Excel文件(2):中规中矩三兄弟xlrd、xlwt和xlutils
本文共3000余字,预计阅读时间14分钟,本文同步发布于知乎(账号silaoA)和微信公众号平台(账号伪码人)。
关注学习了解更多的Cygwin、Linux、Python等技术。
xlrd、xlwt、xlutils是Simplistix公司开发,原网站内容基本都清空了,项目迁移到http://www.python-excel.org,并在GitHub开源,见https://github.com/python-excel。三兄弟在操作Excel方面表现中规中矩,能够覆盖大部分需求,也是本人最先熟悉的库。三兄弟一起配合才能比较方便地实现Excel文件的读写,xlutils不是必需,但额外提供了一些简化操作的工具函数。
0x00 读文件
读文件功能由xlrd包提供。xlrd包实现了xlrd.book.Book(以下简称Book)、xlrd.sheet.Sheet(以下简称Sheet)和xlrd.sheet.Cell(以下简称Cell)类型,与Excel中的工作簿、表单、单元格概念相对应,单元格是最小操作粒度。
API
xlrd没有pyexcel那么花哨,加载表格文件就1个函数——open_workbook,常用参数就2个:
- filename,指定要打开的Excel文件路径;
- on_demand,如果是True则按需加载工作簿中的表单,如果是False则直接加载所有表单,默认为False,为节省资源一般设为True,这在大文件时表现更明显。
示例
假使当前路径下,样例文件名称是data.xls,有3个表单,仅Sheet1有数据,内容如下图,其中C列2行是公式,sum(A2,B2),C列3行是日期,A列4行是TRUE。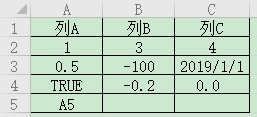
可按下述示例代码加载文件。1
2
3
4
5import xlrd # 导入包
In [4]: rbk = xlrd.open_workbook('./data.xls',on_demand=True)
#变量rbk,r代表读,bk代表book
In [5]: type(rbk)
Out[5]: xlrd.book.Book
0x01 数据访问
工作簿和表单
读入Excel文件拿到Workbook后,下一步就是定位到Sheet。Book类对象有几个重要的属性和方法,用于索引Sheet。
- nsheets属性,指示包含的
Sheet对象个数; - sheet_names方法,返回所有表单名称;
- sheet_by_index、sheet_by_name方法,分别使用序号、名称索引表单;
- sheets方法,返回一个包含所有
Sheet对象的列表,。
1 | In [7]: rbk.nsheets |
拿到Sheet对象后,下一步就是要索引行/列/单元格,获取到行/列/单元格的数据。Sheet类对象有几个重要的属性和方法,用于支持后续操作。
- name属性,即表单名称;
- nrows、ncols属性,指示读入表单的最大行数、列数,由于单元格仅支持行列序号索引,因此这两个属性是检查越界的必备内容;
- cell方法,接受2个参数,即行、列序号,返回
Cell对象,注意xlrd仅支持通过行列序号索引单元格,行列序号从0起始; - cell_value方法,与cell方法类似,只不过返回的是单元格中的值,不是
Cell对象; - cell_type方法,返回单元格的类型,见下图;
- row、col方法,返回某1整行(列)的
Cell对象组成的列表; - row_types、col_types,返回指定行(列)内若干列(行)的单元格的类型;
- row_values、col_values,返回指定行(列)内若干列(行)的单元格的值;
- row_slice、col_slice,返回指定行(列)内若干列(行)的单元格,是types和values的综合。
1 | In [14]: rsh1.nrows, rsh1.ncols # 查看行列上限 |
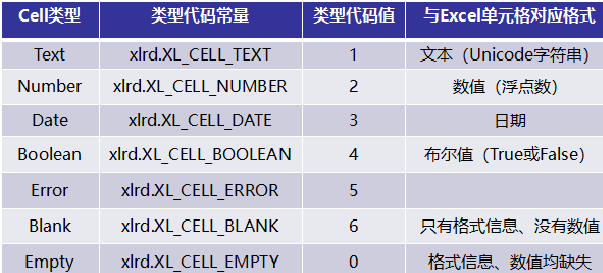
总结以上,xlrd根据单元格的类型返回恰当的值,Number(整数或小数)类型返回的是浮点数,Text类型返回的是Unicode字符串,Boolean(TRUE或False)类型返回的是1或0,Date类型返回浮点数,公式则求值后根据公式值的类型而定。
行、列、单元格
单元格的访问是核心,xlrd包中行、列本质就是Cell对象组成的列表。Cell对象有几个重要属性、方法用于支持获取数据。
- value属性,和
Sheet对象的cell_value方法作用相同; - ctype属性,和
Sheet对象的cell_type方法作用相同; - dump方法,打印单元格信息。
为便于索引,xlrd包的cellname、cellnameabs、colname函数,将行列序号转换为Excel风格的单元格地址;xlwt.Utils模块的rowcol_to_cell、rowcol_pair_to_cellrange函数,也可以将行列序号转换为Excel风格的单元格地址;而col_by_name、cell_to_rowcol、cell_to_rowcol2、cellrange_to_rowcol_pair函数,则将Excel风格的单元格地址转换为行列序号。
1 | In [35]: xlrd.cellname(2,10) |
行列序号与单元格地址转换总结如下图。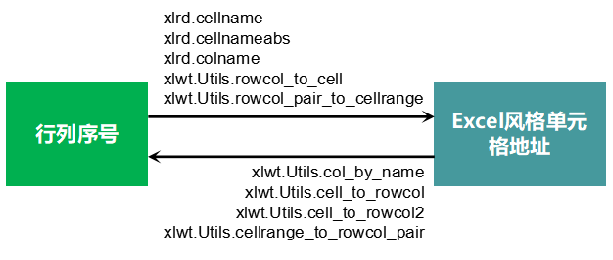
要遍历1个sheet内所有单元格,通常按行、列顺序逐个得到单元格,再读出单元格值存起来,以便后续处理。也可以直接得到一整行(列),整行(列)地处理数据。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18# 1、逐单元格处理
for rx in range(rsh.nrows):
for cx in range(rsh.ncols):
c = rsh.cell(rx, cx)
# 对单元格的进一步处理
print(c.ctype, c.value)
# 2、整行处理
for rx in range(rsh.nrows):
row = rsh.row(rx)
# 对行的进一步处理
print(len(row))
# 3、整列处理
for cx in range(rsh.ncols):
col = rsh.col(cx)
# 对列的进一步处理
print(len(col))
0x02 改写文件
xlrd包只能将表单内的数据读出来,对改写数据无能为力,改写数据和保存至文件,由xlwt包完成。xlwt实现了一套xlwt.Workbook.Workbook(以下简称Workbook)、xlwt.Worksheet.Worksheet(以下简称Worksheet)类型,但很不幸与xlrd包的不存在继承关系,这导致用xlrd包读出来的Book、Sheet对象并不能直接用于创建Workbook和Worksheet对象,只能把数据暂存着以备后续再写回去,使得过程十分繁琐。
API
xlwt包对外暴露的类型、方法、函数及参数也十分简洁,紧密契合改写数据、保存至文件的流程,属于“人狠话不多”的类型。
- 调用
Workbook模块的Workbook函数,创建Workbook对象,第1个参数是encoding,直接默认’ascii’即可; - 调用
Workbook对象的add_sheet方法,往Workbook中添加Worksheet对象,第1个参数sheetname指定表单名称,第2个参数cell_overwrite_ok确定是否允许单元格覆写,建议设置为True,避免对程序可能对单元格多次写数据而抛出错误; - 调用
Worksheet对象的write方法,往Worksheet的行/列/单元格内写入数据,此处用到的数据多数情况来自xlrd包从Excel文件读出来的结果,前2个参数为行列序号,第3个参数是要写入的值,第4个参数是单元格风格,如无特殊需求默认即可; - 调用
Workbook对象的save方法,将Workbook对象保存至文件,参数为文件名称或文件流对象。
其他的属性、方法、函数一般用的较少。
改写与保存示例
假使将前一节data.xls中读出的表格做简单处理,再保存至新的Excel文件。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26import xlwt # 导入库
In [51]: wbk = xlwt.Workbook()
In [52]: type(wbk)
Out[52]: xlwt.Workbook.Workbook
In [53]: wsh1 = wbk.add_sheet("Sheet1", cell_overwrite_ok=True)
In [54]: type(wsh1)
Out[54]: xlwt.Worksheet.Worksheet
# 将rsh1中的数据复制到wsh1,刻意多空1行、1列
In [55]: for rx in range(rsh1.nrows):
...: for cx in range(rsh1.ncols):
...: wsh1.write(rx+1,cx+1,rsh1.cell_value(rx,cx))
In [56]: wsh1.write(0,0, '新数据A1')
In [59]: wsh1.write(0,1, 3.14159)
In [60]: wsh1.write(0,6, False)
In [61]: wsh1.write(4+1,0+1,False) # 覆写原表第4行A列
# 覆写原表第4行D列
In [62]: wsh1.write(3+1, xlwt.Utils.col_by_name('D'),'列D')
经过一番改写,目前所有的改动仍在内存中,调用Workbook对象的save方法,可将数据写入文件中。1
2
3
4
5In [65]: wbk.save('./data2.xls')
In [66]: wbk.save('./data-second.xlsx') # 可以多次保存
In [67]: wbk.save('./data-second.xlsx') # 本质还是xls格式
对于保存,有两点需要提醒:
- Python所有涉及Excel操作的库都不支持“原地编辑与保存”,
xlwt也不例外,“保存”实际上是“另存为”,只是指定保存到原文件的话,原文件被覆盖。 xlwt支持写入到xls格式文件,不支持xlsx格式,即使指定扩展名.xlsx,文件格式本身仍是xls格式。
保存后文件内容如下图。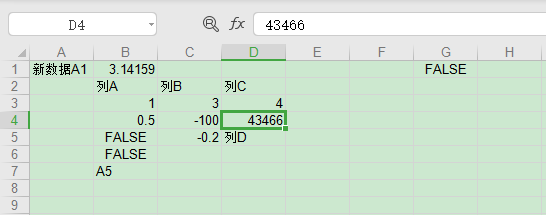
注意从data.xls中读出来的日期,本质是数值,复制后写入还是数值,需要在Excel中将单元格设定为日期格式,才能显示为日期形式。上述写入过程忽略了单元格风格,原data.xls中包含的风格信息被全部丢失。关于单元格风格支持,详见xlwt.Style模块API,风格设置过程繁琐,不如在Excel软件中操作方便,本文不做评述。
xlwt还支持写入公式,但较为有限,比如支持countif却不支持countifs,写入不支持的公式会报错。1
2
3
4# 第3行E列写入公式
In [69]: wsh1.write(2,4, xlwt.Formula('sum(A3:D3)'))
In [70]: wbk.save('./data-含公式.xls')
表格保存后文件内容如下。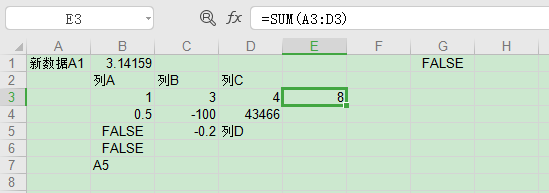
其他辅助
从上述步骤看,如果仅是生成全新的Excel文件,使用xlwt包即可。如果是“编辑”Excel文件中的某些数据,则必须使用xlrd加载原文件并将原表格复制一份,再使用xlwt去处理需要编辑的单元格,流程繁琐。xlutils包的copy正是为简化此流程而生,可以将xlrd的Book对象复制转换为xlwt的Workbook对象。1
2
3
4
5
6
7
8
9
10
11
12
13
14
15import xlutils.copy # 导入模块
# rbk是xlrd载入data.xls文件对应的工作簿,见In [4]
In [78]: wbk2 = xlutils.copy.copy(rbk)
In [79]: wbk2
Out[79]: <xlwt.Workbook.Workbook at 0x15552d5aba8>
In [84]: sh = wbk2.get_sheet(0) # 索引到Sheet1
In [85]: sh.write(0,6,'COPIED')
In [86]: wbk2.add_sheet('表单2') #新增表单
Out[86]: <xlwt.Worksheet.Worksheet at 0x15552cda048>
In [87]: wbk2.save('./data-copy.xls')
xlutils.copy.copy是以工作簿整体复制和转换,原data.xls文件的3个表单均被复制过来,上述代码对Sheet1做了修改,后又增加了新表单,保存后文件内容如下。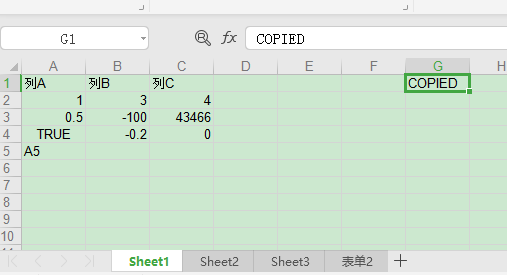
除了copy模块,xlutils包中还有display、filter等模块辅助操作Excel文件。
0x03 总结
从上述读写的示例来看,xlrd负责读、xlwt负责写、xlutils负责提供辅助和衔接,三兄弟各自相对独立而分工明确、配合紧密。xlrd、xlwt、xlutils是以十分原始的方式进行数据访问,流程相对繁琐,好在功能支持方面可以满足大部分需求。
参考
- Working with Excel files in Python,2009. www.python-excel.org
更多阅读
- Python操作Excel文件(1):花式大师pyexcel
- Python操作Excel文件(0):盘点
- Python项目如何合理组织规避import天坑
- Cygwin前传:从割据到互补
- Cygwin系列(一):Cygwin是什么
- Cygwin系列(九):Cygwin学习路线
- Linux Cygwin知识库(一):一文搞清控制台、终端、shell概念
- Linux Cygwin知识库(二):目录、文件及基本操作
- 专栏:伪码人We_Coder
如本文对你有帮助,或内容引起极度舒适,欢迎分享转发或点击下方捐赠按钮打赏 ^_^
- 本文链接:https://silaoa.github.io/2019/2019-12-16-Python操作Excel文件(2):中规中矩三兄弟xlrd、xlwt和xlutils.html
- 版权声明:本文为原创文章,如需转载,请联系stsilaoa@gmail.com 或 公众号 伪码人 或知乎私信 silaoA。